

生徒が自然言語処理に興味を持ったので、あんまり覚えてないなぁと思いつつ、久々に形態素解析やってみっか!ということで、 kuromoji.js を使って日本語の文章を形態素解析して、適当にマルコフ連鎖で文章を作ってみることにしました。
リポジトリの用意
まずは、何はともあれリポジトリの用意から。単純に npm init するだけなのですが、せっかくだし打ったコマンドは全部記録しておきましょう。
$ mkdir kuromoji-example
$ cd kuromoji-example
$ npm init
# この後はエンター連打(特に公開するつもりもないし)
$ git init
$ echo "node_modules" >> .gitignore
$ git add .
$ git commit -m "Init repository"
node_modules を .gitignore に入れておかないと、リポジトリに依存する npm package のコードが全部コミットされてしまって大変なので、忘れずにやっておきましょう。
kuromoji.js のインストール
npm install もしくは省略して npm i で kuromoji.js をインストールするんですが、この際 --save (もしくは省略形で -S)をつけておくと、 package.json に自動で依存を追記しておいてくれます。便利なので活用しましょう。ってことで何はともあれ npm i 。
$ npm install -S kuromoji
$ git add package.json
$ git commit -m "Install kuromoji"
まずは形態素解析してみる
kuromoji.js のインストールもつつがなく終わりましたし、とりあえずで形態素解析してみます。形態素解析ってなんだ。
形態素解析
この単語、どこで区切るんだ……?と混乱しそうになりますが、『形態素』と『解析』で分けます。ということで一番見慣れない『形態素』ってなんぞや、というところから。
形態素
形態素(けいたいそ、英: morpheme)とは、言語学の用語で、意味を持つ最小の単位。ある言語においてそれ以上分解したら意味をなさなくなるところまで分割して抽出された、音素のまとまりの1つ1つを指す。形態素の一般的な性質や、形態素間の結びつきなどを明らかにする言語学の領域は、形態論と呼ばれる。
さすがの Wikipedia 先生。いつでも『わかりそうでちょっとわからない、真剣に読むと全然わからない』要約ですね。
形態素に分ける
とどのつまり、形態素というのは一文に含まれる言葉たちの意味を持つ最小の単位のことです。英語だと単に空白とアポストロフィーあたりを参考にわければ良いのですが(まぁ、それだけじゃ済まないと思うけど)、日本語だと少々事情が異なります。例えば
今日は森へ行った
という文と
今日は森林浴をした
には双方『森』という文字が出てきますが、前者の文では『森』という一般名詞の単語。後者では『森林浴』という一般名詞のを構成する1文字、というように、同じ文字でも『最小の意味か』という点では異なります。
こういった形態素をきちんと解析するには『どういう文字の並びだと名詞か』とか『どうつながってるとある文字は助詞か』なんていうのを考慮しないといけません。ということで、形態素解析には辞書が必須なのです。
kuromoji で利用する辞書
kuromoji.js にはインストール時に辞書があらかじめ付いているので、今回はその辞書を使って形態素解析を実行してみましょう。前段の説明でイマイチピンとこなかったかもしれませんが、実際に分けられてみると納得ものです。
kuromoji.js で形態素解析
さっそくプログラム書いていこう、ということで、 index.js に以下の内容を書いて実行してみましょう。
var kuromoji = require('kuromoji');
// この builder が辞書やら何やらをみて、形態素解析機を造ってくれるオブジェクトです。
var builder = kuromoji.builder({
// ここで辞書があるパスを指定します。今回は kuromoji.js 標準の辞書があるディレクトリを指定
dicPath: 'node_modules/kuromoji/dist/dict'
});
// 形態素解析機を作るメソッド
builder.build(function(err, tokenizer) {
// 辞書がなかったりするとここでエラーになります(´・ω・`)
if(err) { throw err; }
// tokenizer.tokenize に文字列を渡すと、その文を形態素解析してくれます。
var tokens = tokenizer.tokenize("今日は森へ行った");
console.dir(tokens);
});
$ node index.js
ちょっと長いですが、こんな出力が返ってきたんではなかろうかと思います。
[ { word_id: 351380,
word_type: 'KNOWN',
word_position: 1,
surface_form: '今日',
pos: '名詞',
pos_detail_1: '副詞可能',
pos_detail_2: '*',
pos_detail_3: '*',
conjugated_type: '*',
conjugated_form: '*',
basic_form: '今日',
reading: 'キョウ',
pronunciation: 'キョー' },
{ word_id: 2595270,
word_type: 'KNOWN',
word_position: 3,
surface_form: 'は',
pos: '助詞',
pos_detail_1: '係助詞',
pos_detail_2: '*',
pos_detail_3: '*',
conjugated_type: '*',
conjugated_form: '*',
basic_form: 'は',
reading: 'ハ',
pronunciation: 'ワ' },
{ word_id: 900290,
word_type: 'KNOWN',
word_position: 4,
surface_form: '森',
pos: '名詞',
pos_detail_1: '一般',
pos_detail_2: '*',
pos_detail_3: '*',
conjugated_type: '*',
conjugated_form: '*',
basic_form: '森',
reading: 'モリ',
pronunciation: 'モリ' },
{ word_id: 2594520,
word_type: 'KNOWN',
word_position: 5,
surface_form: 'へ',
pos: '助詞',
pos_detail_1: '格助詞',
pos_detail_2: '一般',
pos_detail_3: '*',
conjugated_type: '*',
conjugated_form: '*',
basic_form: 'へ',
reading: 'ヘ',
pronunciation: 'エ' },
{ word_id: 3452760,
word_type: 'KNOWN',
word_position: 6,
surface_form: '行っ',
pos: '動詞',
pos_detail_1: '自立',
pos_detail_2: '*',
pos_detail_3: '*',
conjugated_type: '五段・カ行促音便',
conjugated_form: '連用タ接続',
basic_form: '行く',
reading: 'イッ',
pronunciation: 'イッ' },
{ word_id: 304750,
word_type: 'KNOWN',
word_position: 8,
surface_form: 'た',
pos: '助動詞',
pos_detail_1: '*',
pos_detail_2: '*',
pos_detail_3: '*',
conjugated_type: '特殊・タ',
conjugated_form: '基本形',
basic_form: 'た',
reading: 'タ',
pronunciation: 'タ' } ]
形態素の配列が返ってきていることがわかるでしょうか?それぞれ形態素はいくつかのプロパティを持っています。僕もあんまり自然言語処理には詳しくないので詳細に説明は出来ないのですが、大体
word_id: 単語の ID (よくわからん)word_type:KNOWNかUNKNOWNが入っているっぽいので、辞書にある単語かそうでないかだと思われます。word_position: 文中の形態素の位置surface_form: 文中の表記pos: 品詞pos_detail_*: 品詞のなんかもうちょい詳細conjugated_type: 活用の種類conjugated_form: 活用basic_form: 基本形reading: 読み仮名pronunciation: 読み仮名(音)
みたいな意味かと思われます(間違ってたらすまん!)
とにもかくにも形態素解析そのものは出来たっぽい感じがするので、成功ということにしましょう。詳しく知るのは後からでも遅くない!今は遊ぶ!
マルコフ連鎖で遊ぼう
マルコフ過程とマルコフ連鎖とは
マルコフ過程とは『未来の状態が、過去の状態によらず、現在の状態のみで確率が決定する』という性質を持つ確率過程です。ちょっと難しいので、具体的な図を用意しました。
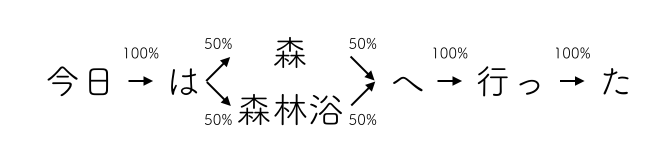
上のような図の時、本来『今日は』の後に続く単語は本当に今日僕がどこへ行ったのかで何を言うか確率が変わるのですが、それらの状況や過程を一切無視して、これまで形態素解析して得られた『とある単語の次に現れたのは何か』という確率だけで判定しています。
もっと正確に言えば『今日』の次に『は』がくる確率が 100% 、『は』の次に『森』と『森林浴』が続く可能性が 50% ずつ、という確率です。
形態素解析とマルコフ連鎖を用いて文章を生成すると『日本語としてはまぁ正しくないこともないんだけど、意味がぜんぜんつながってなくてわけわからん!』という不思議な文章を作る事ができます。
JavaScript でマルコフ連鎖
マルコフ過程は、確率を決定する際、単純に現在の事柄だけ注目する単純マルコフ過程、直前を含む連続した N 個の状態をから次が決まる N 階マルコフ過程があり、単純マルコフ過程は bi-gram(2-gram) 、 N 階マルコフ過程はそのまま N-gram なインデックスとして作ることが出来ます。
ということでなんかしら文章を学ばせるために、ソースデータが必要そうです。
ご用意しました。こちら、アシタカ先輩の全セリフです。アシタカ先輩『くっ』とか『ぐっ』とかばっかり喋ってて不安になるんですが、まぁ多分大丈夫でしょう。
まぁデータもあるし、さっそくマルコフ連鎖をしていくコードを書きましょう。
コードを書く
今回は単純に直前の文字だけを気にするマルコフ連鎖を作ります。なので、実装は Object の key として直前の文字を、その値として、続く文字の配列を作ってあげます。文の最初と最後は null として扱うようにしましょう。
細かい説明はコードを読んで頂くとして、出来上がるコードがこんな感じです。 markov.js という名前で作りました。
var fs = require('fs');
// kuromoji 周りの設定とか
var kuromoji = require('kuromoji');
var builder = kuromoji.builder({
dicPath: 'node_modules/kuromoji/dist/dict'
});
// マルコフ連鎖の実装
class Markov {
constructor(n) {
this.data = {};
}
// データ登録
add(words) {
for(var i = 0; i <= words.length; i++) {
var now = words[i];
if(now === undefined) { now = null };
var prev = words[i - 1];
if(prev === undefined) { prev = null };
if(this.data[prev] === undefined) {
this.data[prev] = [];
}
this.data[prev].push(now);
}
}
// 指定された文字に続く文字をランダムに返す
sample(word) {
var words = this.data[word];
if(words === undefined) { words = []; }
return words[Math.floor(Math.random() * words.length)];
}
// マルコフ連鎖でつなげた文を返す
make() {
var sentence = [];
var word = this.sample(null);
while(word) {
sentence.push(word);
word = this.sample(word);
}
return sentence.join('');
}
}
var markov = new Markov();
builder.build(function(err, tokenizer) {
if(err) { throw err; }
// アシタカ先輩の台詞を読み込む
fs.readFile('ashitaka.txt', 'utf8', function(err, data) {
if(err) { throw err; }
var lines = data.split("\n"); // 一行ごとに分割
lines.forEach(function(line) {
var tokens = tokenizer.tokenize(line);
// トークンを文中表記にすべて変換
var words = tokens.map(function(token) {
return token.surface_form;
});
// データを登録
markov.add(words);
});
// 10回くらい生成してみる
for(var n = 0; n < 10; n++) {
console.log(markov.make());
}
});
});
$ node markov.js
結果
カヤ!
あなたは…
やめろ-っしょうぶしょうぶ!
…シシ神よ、サンはまちがいでしたことは美しい…
タタラ場からかわってよ、まてェ!
くっ!行こう
ふしぎな
なにか来る!
やめろ-っしょうぶしょうぶ!アシタカがエボシ!
やめろ!
カヤ誰だよ。多分『アシタカ』と『ヤックル』が連続した時があったんだろうと思うけど……w
あとなにげにサンをディスってるのウケる。『アシタカがエボシ!』も破壊力高い。でもなんとなくアシタカさんがいいそうな感じの文章になってるのがこれまた腹筋に悪いですね。
ソースデータを変えてもいろいろ面白くなるかもしれません。是非試してみてください。
おまけ
マルコフ連鎖で出てきた台詞でいくつか面白いのを抜粋しておきました。君も君だけのオリジナル嘘台詞を見つけよう!
おもしろアシタカ嘘台詞
- 美しい… : シンプル
- 首を射るとき心を伝えたい : シリアルキラーかお前は
- モロ…人間だ!みすみす死ぬなァ! : モロは人間じゃないだろ!!
- 山犬はいたの : いたよ
- シシ神を切るから : 何言ってんだお前は